Google stworzyło Imagen, najstraszniejszy program na świecie. SI przetwarza słowa na fotorealistyczne obrazy
 Oliwier Nytko,26.05.2022 15:00
Oliwier Nytko,26.05.2022 15:00Czy Google kiedyś przejmie kontrolę nad światem? Nie wiem. Ale czy właśnie zostało stworzone genialne SI, które nauczyło się tworzyć zdjęcia na podstawie kilku słów? Tak - i to wygląda tak dobrze, że aż przerażająco.
Google z jednej strony wydaje się bardzo potulną i miłą korporacją, tworzącą fajny system Android czy YouTube. Z drugiej strony firma chwali się swoimi odkryciami - i te czasem potrafią przerazić. Kiedyś obawialiśmy się noszenia "smart okularów" z wbudowanym aparatem, a teraz… teraz powstała SI, która tworzy obrazy na podstawie słów.
Podobne
- Google ma bata na AI. Pokaże, które obrazy są fałszywe
- Google po interwencji Vibeza zamknął nowy patokanał Jaszczura
- YouTube wprowadził dubbing. Czy skorzystają na nim polscy twórcy?
- Polak poszedł na całość. Niesamowite, co zbudował w ogrodzie
- Elon Musk przejmuje Twittera… no, 9,2% udziałów. Pora na EDYCJĘ tweetów?




*SI = Sztuczna Inteligencja.
Google z SI przetwarzającym słowa na fotorealistyczne obrazy
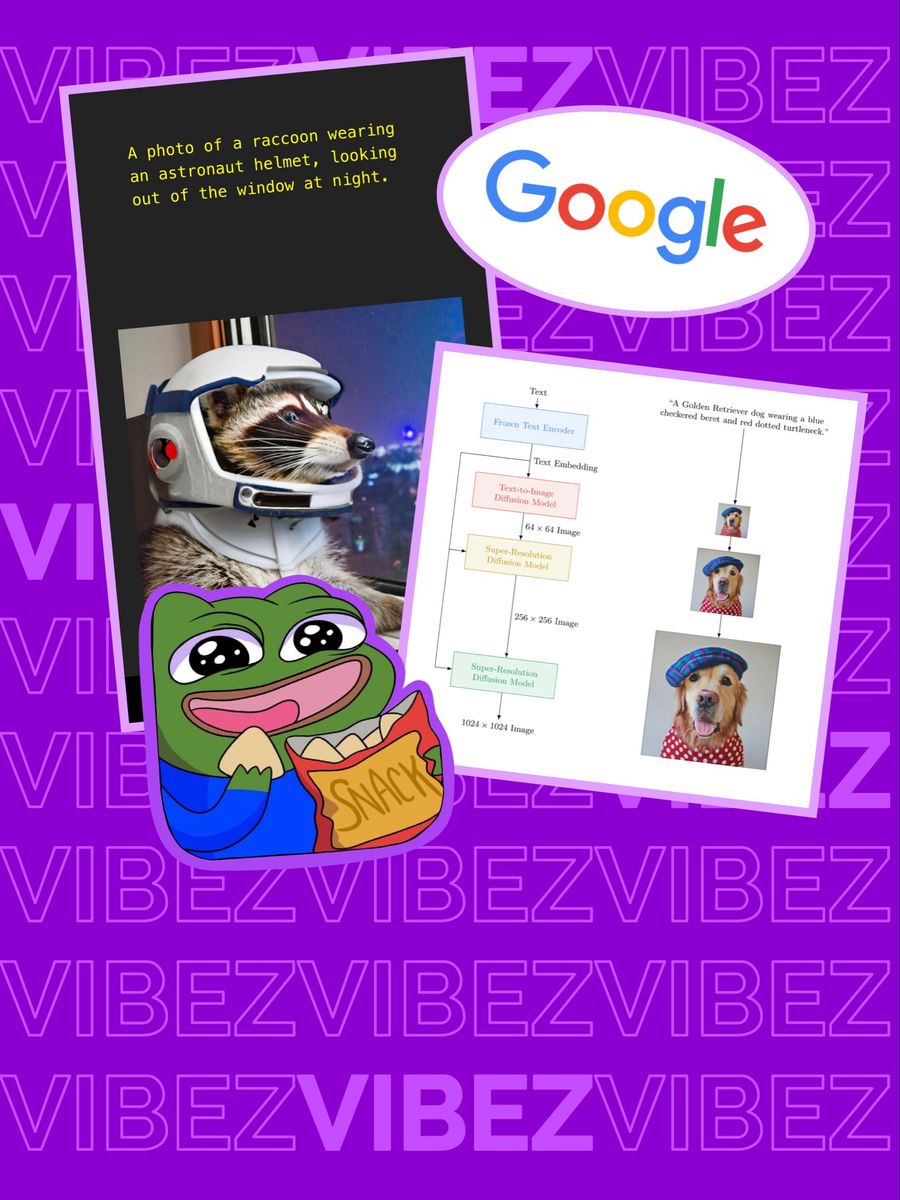
Imagen to nazwa SI, która jest w stanie przetworzyć jakieś słowo, np. "pies w kapeluszu" i stworzyć na jego podstawie obraz, który nierzadko trudno byłoby odróżnić od rzeczywistości. Wszystko ma działać na podstawie sztucznej inteligencji i nauczania maszynowego.
Celem autorów było stworzenie programu, który jest w stanie tworzyć niemożliwe do odróżnienia od rzeczywistości obrazy. Poniżej znajduje się przykład tego, co system może utworzyć na podstawie opisu: "łysy orzeł z czekolady w proszku, mango i bitej śmietany":

"Smoczy owoc ubrany w pas karate na śniegu":

"Zdjęcie psa rasy Corgi jadącego na rowerze na Times Square. Ma na sobie okulary przeciwsłoneczne i kapelusz plażowy":

Imagen nie dla szerszej publiki?
Jak podaje m.in. serwis Engadget, Imagen nie jest dostępny publicznie. Google uważa, że nie nadaje się on jeszcze do powszechnego użytku z kilku powodów. Problemem jest m.in. pobieranie próbek z sieci, co tworzy swoje problemy:
Chociaż takie podejście umożliwiło szybki postęp algorytmiczny w ostatnich latach, zbiory danych tego rodzaju często odzwierciedlają społeczne stereotypy, opresyjne punkty widzenia i uwłaczające lub w inny sposób szkodliwe skojarzenia z marginalizowanymi grupami tożsamości.
Chociaż podzbiór naszych danych szkoleniowych został przefiltrowany w celu usunięcia szumu i niepożądanych treści, takich jak obrazy pornograficzne i toksyczny język, wykorzystaliśmy również zbiór danych LAION-400M, o którym wiadomo, że zawiera szeroki zakres nieodpowiednich treści, w tym obrazy pornograficzne, rasistowskie obelgi i szkodliwe stereotypy społeczne - piszą naukowcy w swojej pracy.
Jak twierdzą badacze, z tego powodu Google Imagen odziedziczył "społeczne uprzedzenia i ograniczenia dużych modeli językowych" i może przedstawiać "szkodliwe stereotypy i reprezentacje".
Źródło: Engadget, imagen.research.google






W temacie popkultura
- Kosma Król: "Całe życie underground, całe życie nisza". Raper o muzyce, trendach i festiwalach [WYWIAD]
- Daniel Godson zrobił "krok wiary" i rzucił pracę dla muzyki. Zagrał koncert na Open'erze, PGE Narodowym i support przed OneRepublic [WYWIAD]
- TOP 5 koncertów na Open'er Festivalu. Wielkość nazwisk na plakacie nie zawsze ma znaczenie? [RECENZJA]
- Czy opłaca się kupować bilety VIP? Prosta girl math [VIBEZ IN LINE]
![Kosma Król: "Całe życie underground, całe życie nisza". Raper o muzyce, trendach i festiwalach [WYWIAD]](https://v.wpimg.pl/OTY0OTA1YDU4UjlnbkptIHsKbT0oE2N2LBJ1dm4DfmchAndsblcmODxCKiQuHygmLEAuIzEfPzh2UT89bkd-ez1ZPCQtUDZ7PF0tMSUeemxtAX1jIlBiZGgIf3l1Bn5idFF-YXccKTU_VnZidQh_YW9TbSk)
![Daniel Godson zrobił "krok wiary" i rzucił pracę dla muzyki. Zagrał koncert na Open'erze, PGE Narodowym i support przed OneRepublic [WYWIAD]](https://v.wpimg.pl/YjQ3Y2UzdgswUS8BegF7HnMJe1s8WHVIJBFjEHpIaFkpAWEKehwwBjRBPEI6VD4YJEM4RSVUKQZ-UilbegxoRTVaKkI5GyBFNF47VzFVbgthC2pTMUl0XmNVah9hGGtSfFJoAzdXbVo1VjsGYhk8WWcCe08)
![TOP 5 koncertów na Open'er Festivalu. Wielkość nazwisk na plakacie nie zawsze ma znaczenie? [RECENZJA]](https://v.wpimg.pl/NzIxNDM2YRsoGjh3YklsDmtCbC0kEGJYPFp0ZmIAf0kxSnZ8YlQnFiwKKzQiHCkIPAgvMz0cPhZmGT4tYkR_VS0RPTQhUzdVLBUsISkdf0x7Hnh9eANjGXtBdml5VihLZEEoIXkfeh54TXl2fAZ9TH1KbDk)
![Czy opłaca się kupować bilety VIP? Prosta girl math [VIBEZ IN LINE]](https://v.wpimg.pl/MGJhYWJkYiYrCi9kZRBvM2hSez4jSWFlP0pjdWVZfHQyWmFvZQ0kKy8aPCclRSo1Pxg4IDpFPStlCSk-ZR18aC4BKicmCjRoLwU7Mi5EKyZ6Dj1gfg1gdHIKbnp-DX51ZwphZntGdCIvWmk1KwovIyhceyo)
